Bayesian Ordinal Regression for Crop Development and Disease Assessment
26/11/2025
Experiments
Objective: evaluating deep sowing of oats in WA production systems
Design: split-plot design at two sites
Sowing depths at 30, 80 and 120 mm
Variety-herbicide combinations: 10 levels
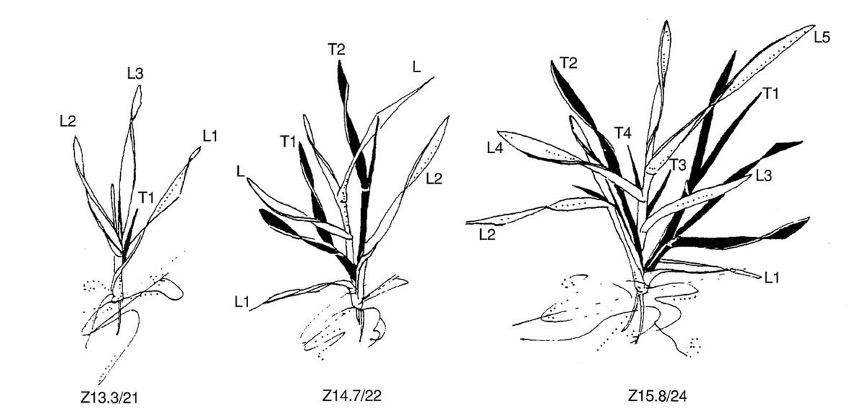
Zadoks growth scale
The Zadok’s growth scale is based on ten principal cereal growth stages (Zadoks, Chang, and Konzak (1974)):
0 - Germination
1 - Seeding growth
2 - Tillering
3 - Stem elongation
4 - Booting
5 - Awn emergence
6 - Flowering (anthesis)
7 - Milk development
8 - Dough development
9 - Ripening
Initial data exploration
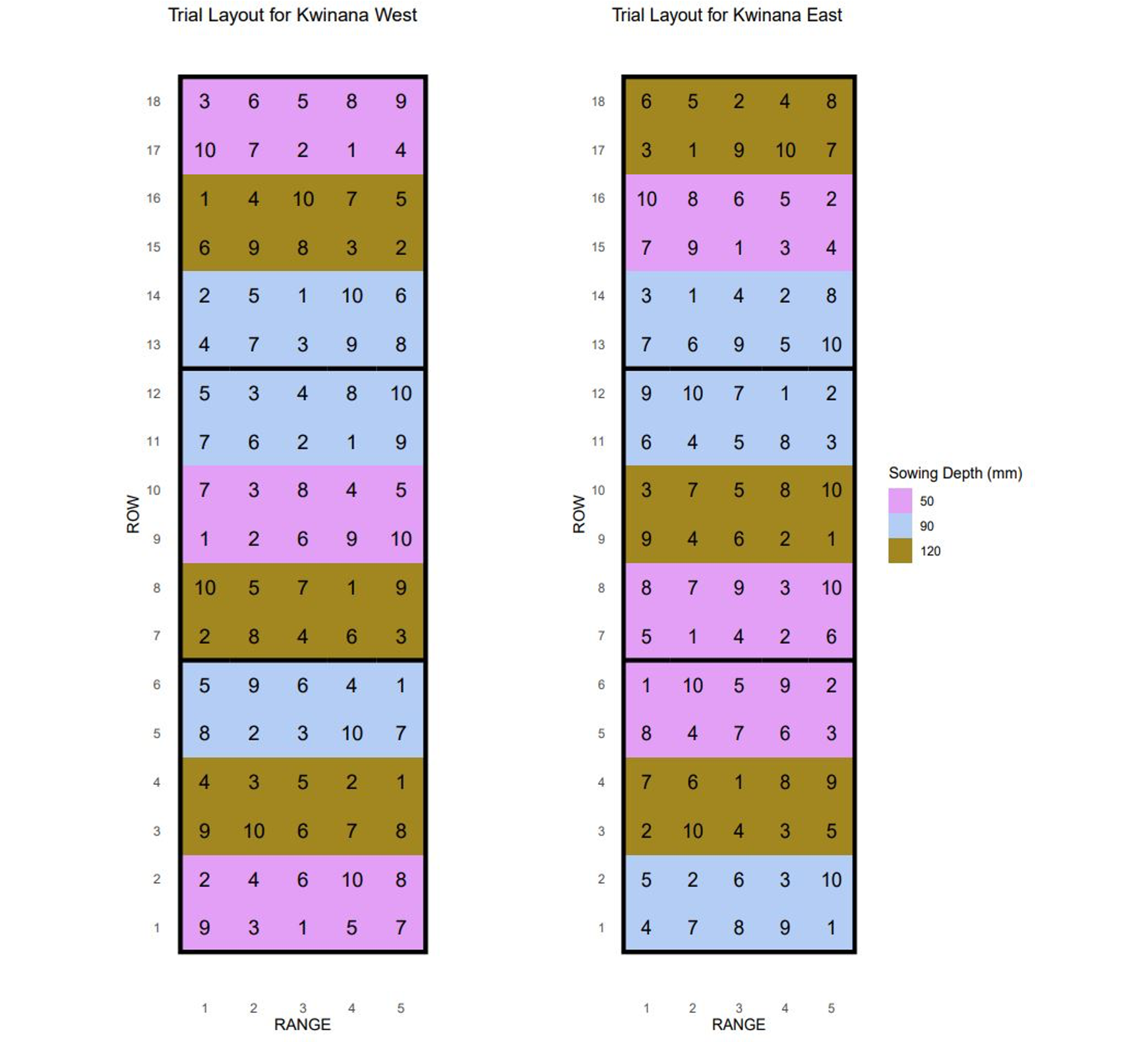
The spatial effect
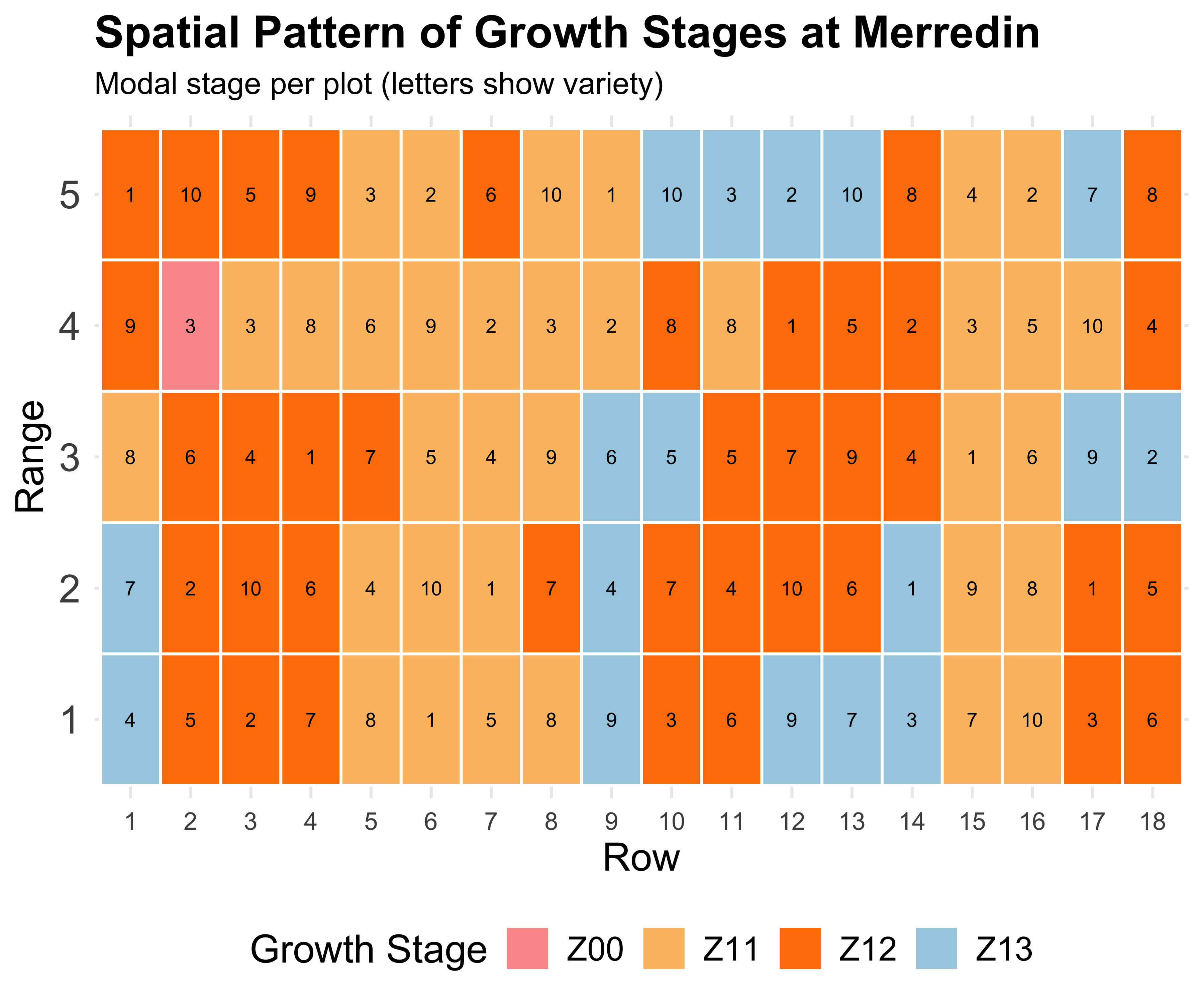
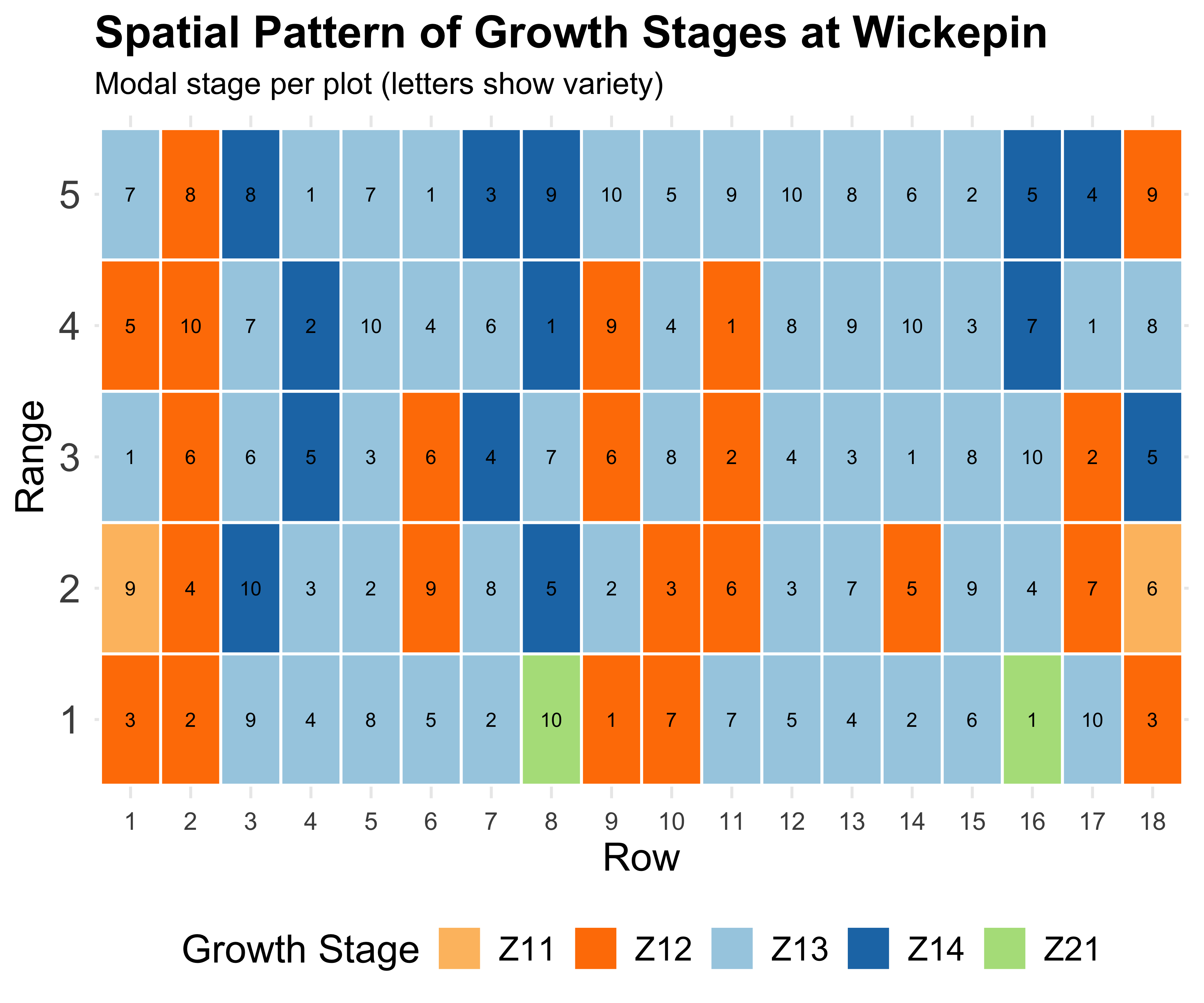
Field trials have spatial gradients
Better estimates → Better decisions
Bayesian approach

Choosing the right ordinal model
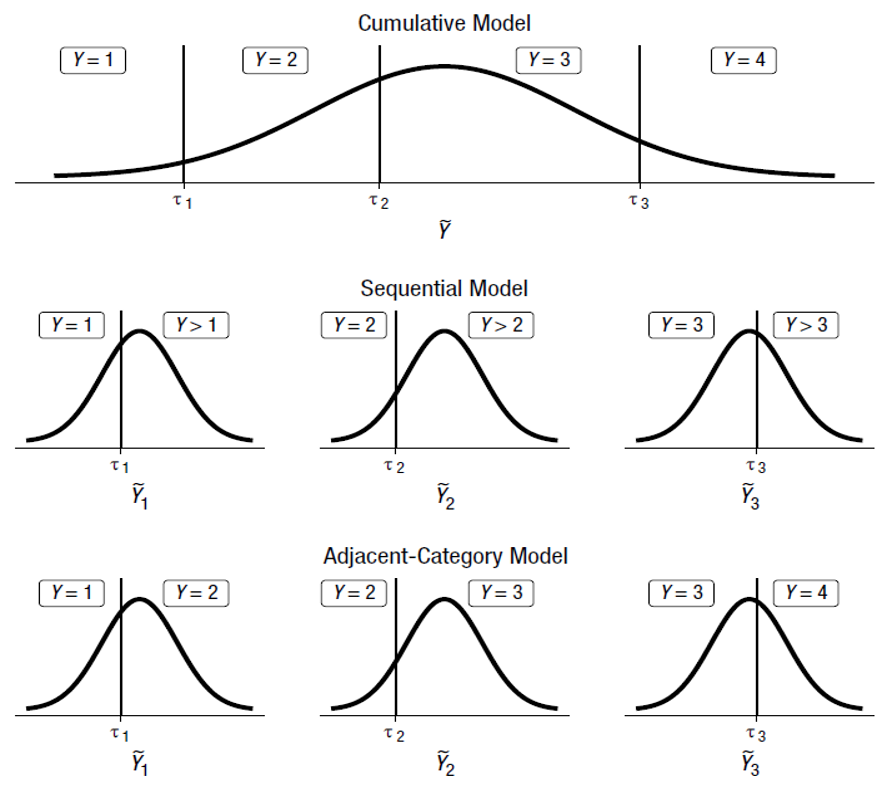
Source: Bürkner and Vuorre (2019)
Bayesian workflow
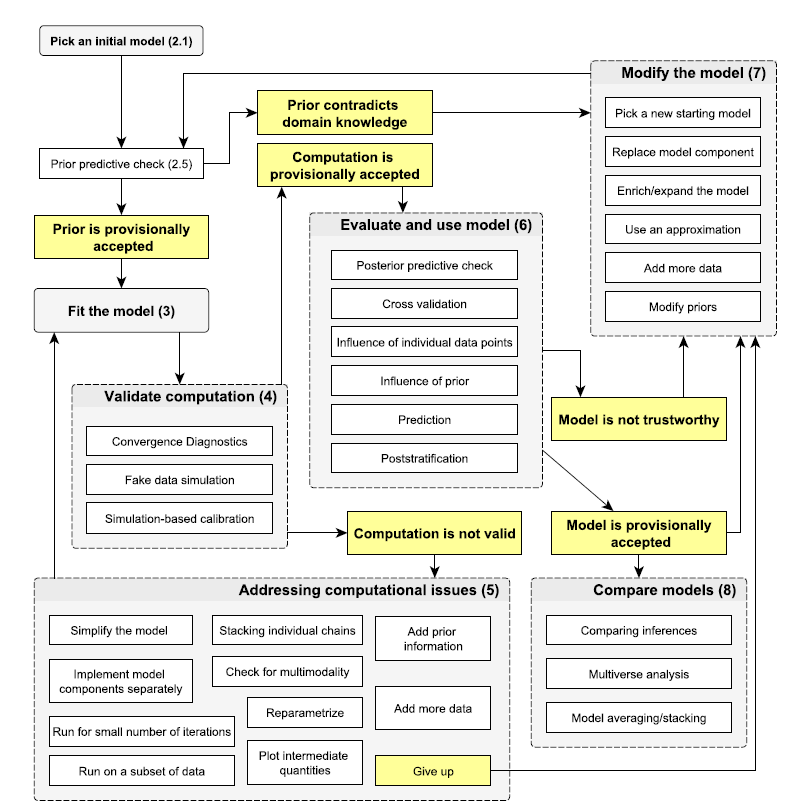
(source: Gelman et al. (2020))

Model comparison
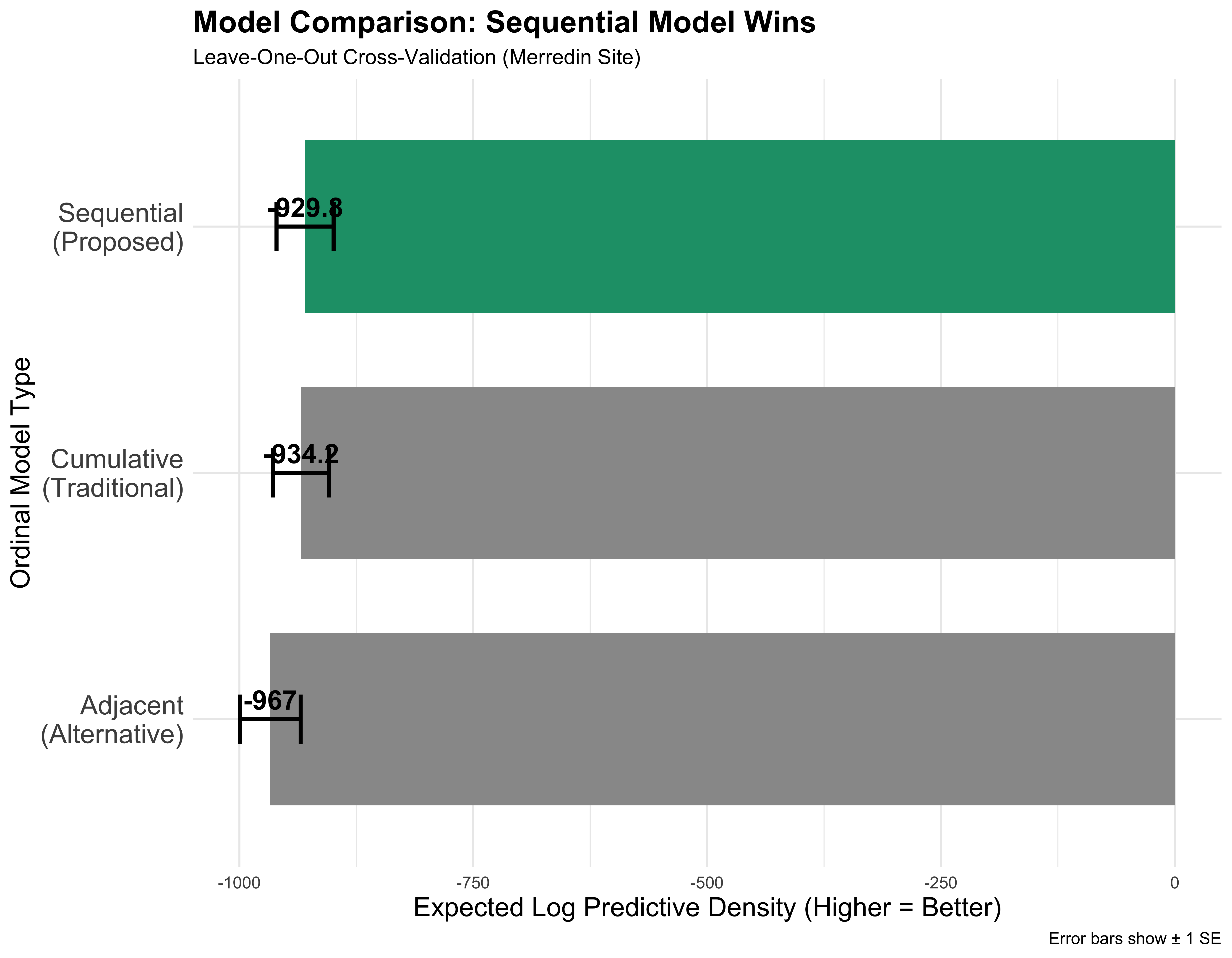
Winner: Sequential for Better ELPD + biologically interpretable!
- Cumulative (proportional odds)
- Models: \(P(Y \leq k)\)
- Interpretation: “At or below stage \(k\)”
- Sequential (continuation ratio) ✅
- Models: \(P(Y \leq k | Y \leq k-1)\)
- Interpretation: “Advance to next stage”
- Adjacent-category
- Models: \(P(Y = k \mid Y \in \{k, k+1\})\)
- Interpretation: “Adjacent stage ratios”
Model diagnostics
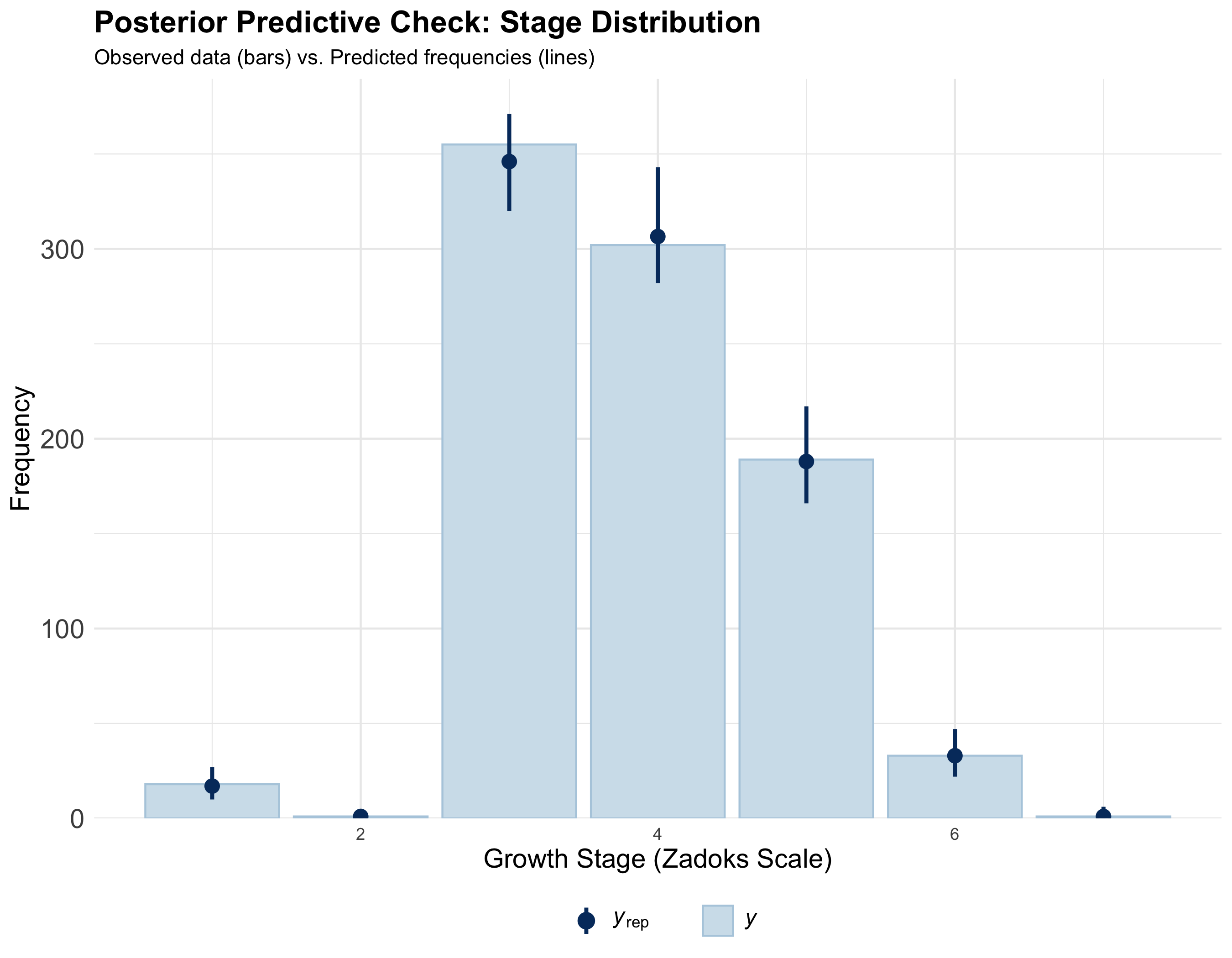
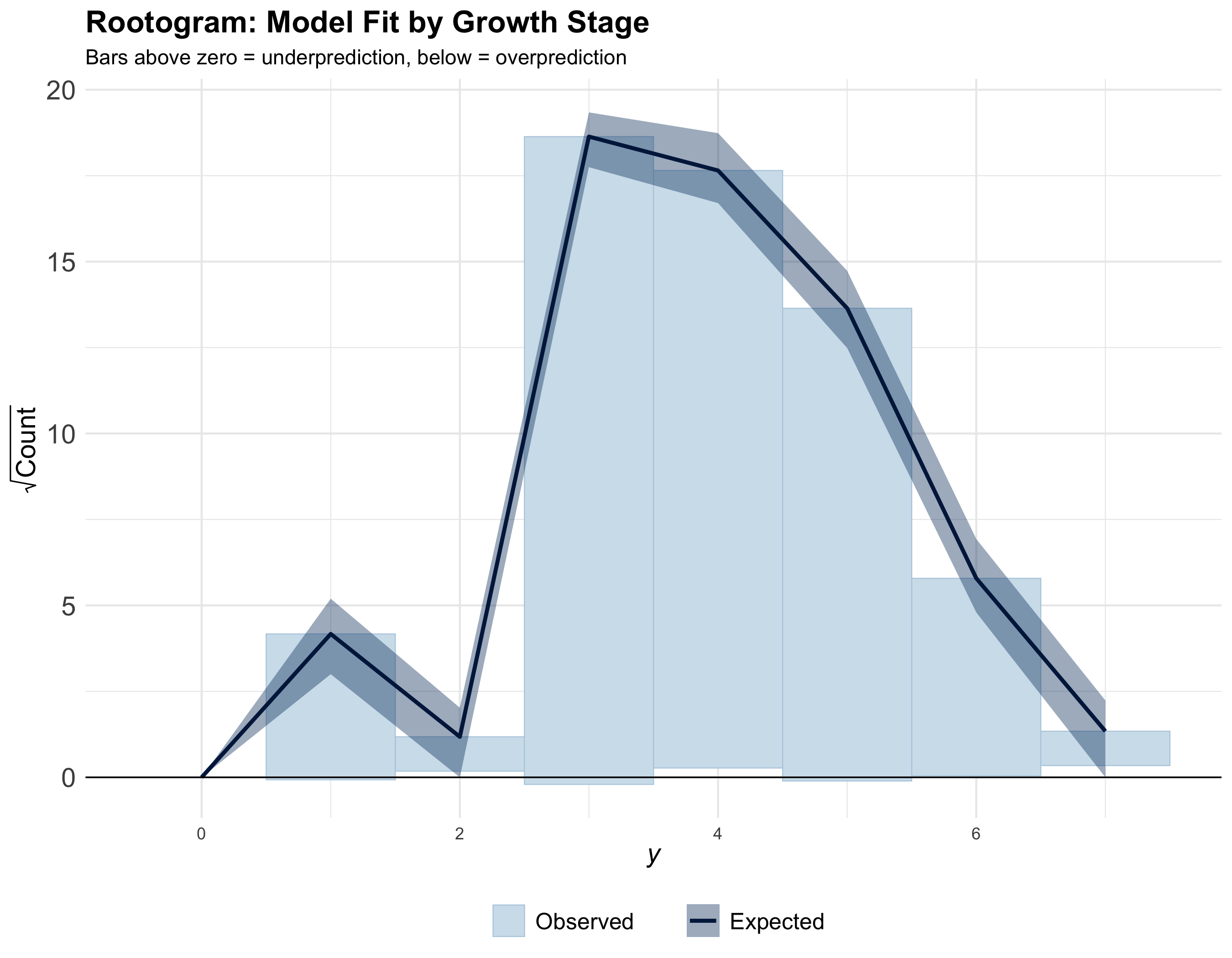
Also refer to Cao et al. (2022) for detailed diagnostics.
Results
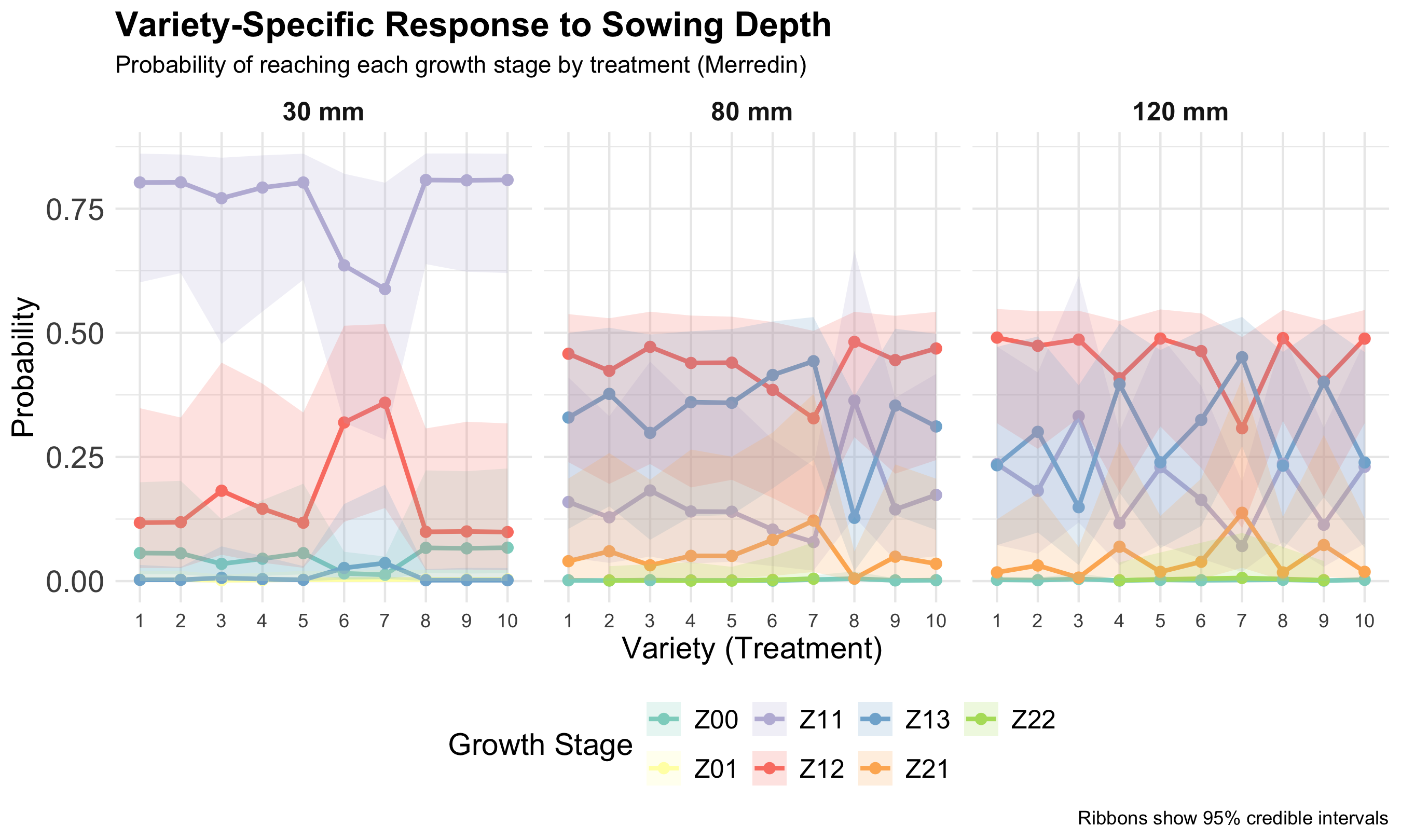
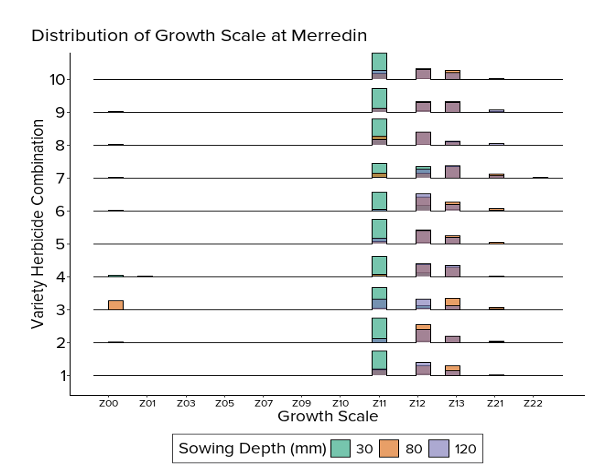
Variety-specific response by sowing depth (Merredin); ribbons show 95% credible intervals.
Results
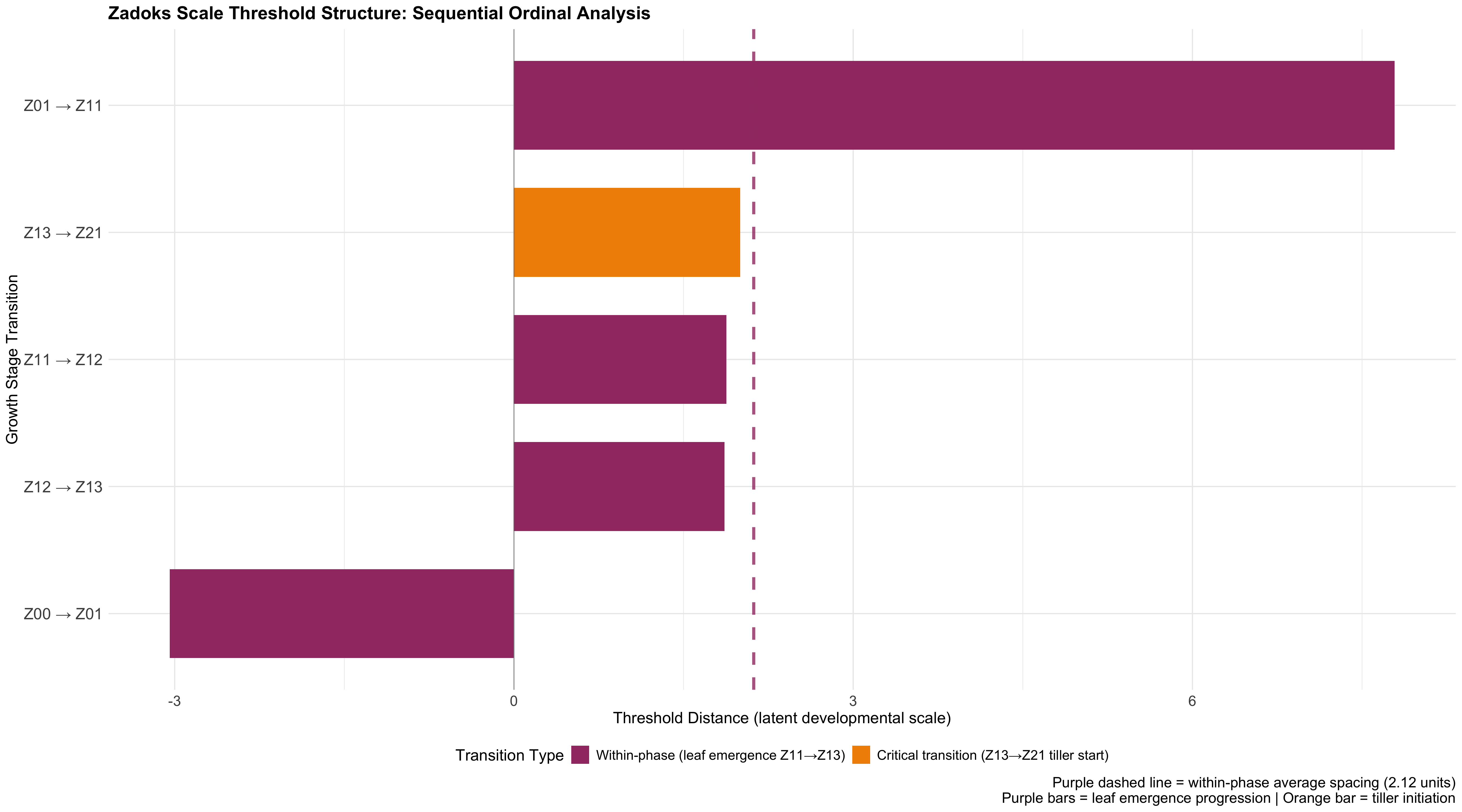
What this shows:
- Clear threshold between seed emerge (Z01) and leaf development (Z11). This explains why sowing depth affects it most strongly!
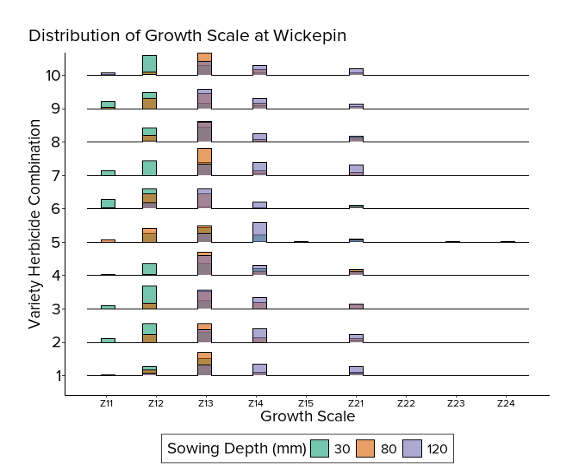
Site consistency
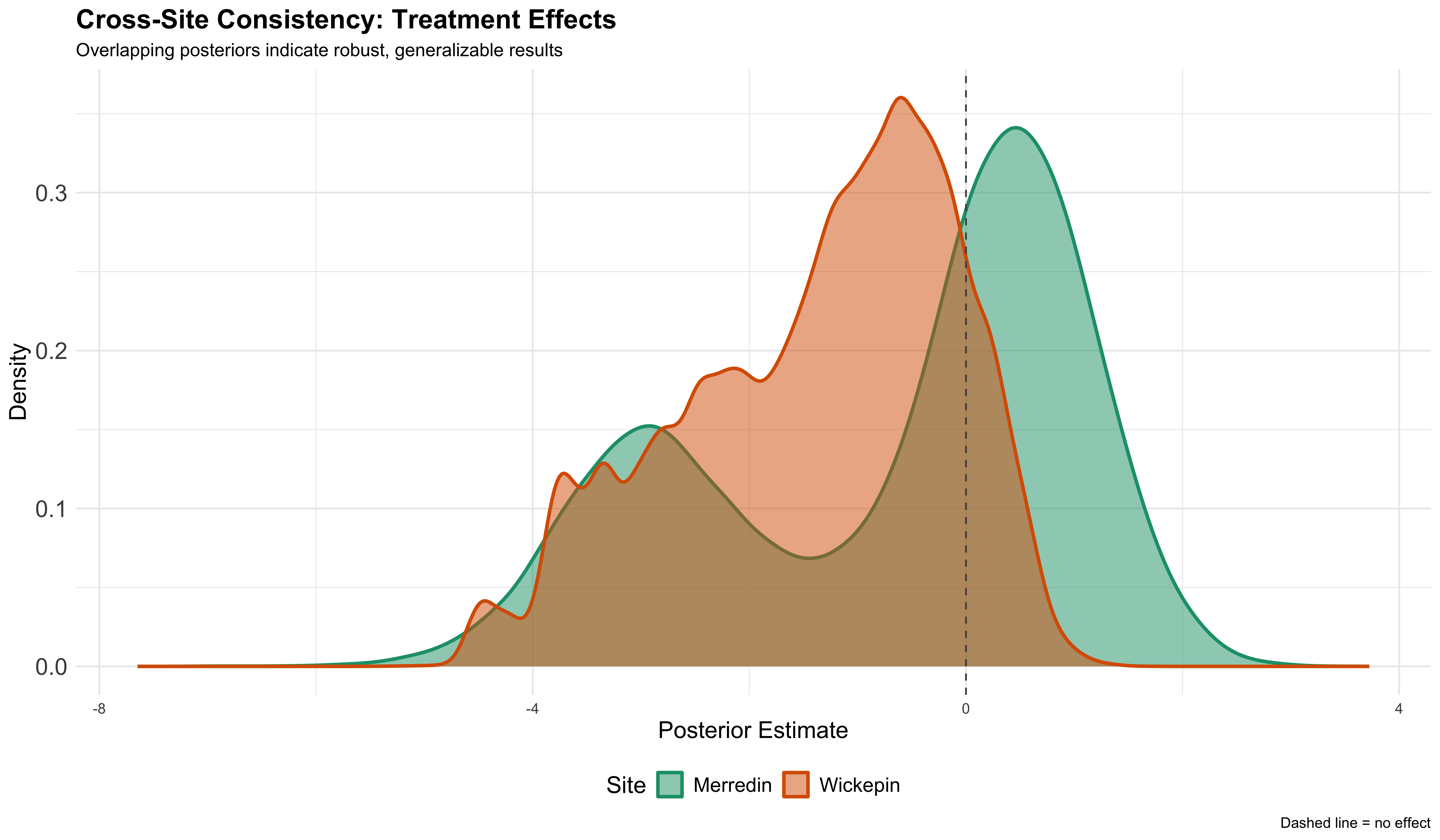
Treatment effects comparison across Merredin and Wickepin
Acknowledgments
People:
- Rose Megirian
- Matthew Nguyen
- Professor Adam Sparks
- All Growers
![]()

Funding & Support: 
